聊什么
在《Apache Flink 漫谈系列 - SQL概览》中我们介绍了JOIN算子的语义和基本的使用方式,介绍过程中大家发现Apache Flink在语法语义上是遵循ANSI-SQL标准的,那么再深思一下传统数据库为啥需要有JOIN算子呢?在实现原理上面Apache Flink内部实现和传统数据库有什么区别呢?本篇将详尽的为大家介绍传统数据库为什么需要JOIN算子,以及JOIN算子在Apache Flink中的底层实现原理和在实际使用中的优化!
什么是JOIN
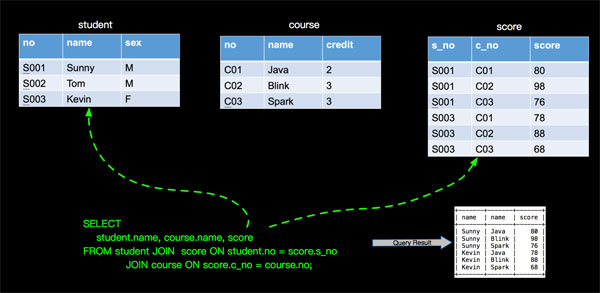
在《Apache Flink 漫谈系列 - SQL概览》中我对JOIN算子有过简单的介绍,这里我们以具体实例的方式让大家对JOIN算子加深印象。JOIN的本质是分别从N(N>=1)张表中获取不同的字段,进而得到最完整的记录行。比如我们有一个查询需求:在学生表(学号,姓名,性别),课程表(课程号,课程名,学分)和成绩表(学号,课程号,分数)中查询所有学生的姓名,课程名和考试分数。如下:
为啥需要JOIN
JOIN的本质是数据拼接,那么如果我们将所有数据列存储在一张大表中,是不是就不需要JOIN了呢?如果真的能将所需的数据都在一张表存储,我想就真的不需要JOIN的算子了,但现实业务中真的能做到将所需数据放到同一张大表里面吗?答案是否定的,核心原因有2个:
(1)产生数据的源头可能不是一个系统;
(2)产生数据的源头是同一个系统,但是数据冗余的沉重代价,迫使我们会遵循数据库范式,进行表的设计。简说NF如下:
1NF - 列不可再分;2NF - 符合1NF,并且非主键属性全部依赖于主键属性;3NF - 符合2NF,并且消除传递依赖,即:任何字段不能由其他字段派生出来;BCNF - 符合3NF,并且主键属性之间无依赖关系。当然还有 4NF,5NF,不过在实际的数据库设计过程中做到BCNF已经足够了!(并非否定4NF,5NF存在的意义,只是个人还没有遇到一定要用4NF,5NF的场景,设计往往会按存储成本,查询性能等综合因素考量)
JOIN种类
JOIN 在传统数据库中有如下分类:
(1)CROSS JOIN - 交叉连接,计算笛卡儿积;
(2)INNER JOIN - 内连接,返回满足条件的记录;
(3)OUTER JOIN
LEFT - 返回左表所有行,右表不存在补NULL;RIGHT - 返回右表所有行,左边不存在补NULL;FULL - 返回左表和右表的并集,不存在一边补NULL;(4)SELF JOIN - 自连接,将表查询时候命名不同的别名。
JOIN语法
JOIN 在SQL89和SQL92中有不同的语法,以INNER JOIN为例说明:
SQL89 - 表之间用“,”逗号分割,